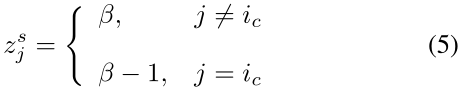Object Instance Mining for Weakly Supervised Object Detection
商汤科技 & 大连理工 2020
一。简介
目的:解决弱监督目标检测中单张图片里出现多个对象实例的情况(在无目标对象数量标注的情况下充分挖掘proposals中的正样本,替代C-WSL的工作)。试图仅利用图像级监督来精确挖掘每个图像中所有可能的对象实例,防止模型学习过程陷入局部最优。
基于两个假设分别建立空间图和外观图:
(1)与最高置信度的proposals的IoU很大的proposals,它们的标签应当相同;
(2)同一类的对象应该具有很高的外观相似度。
关键贡献:
(1)提出了一种利用空间图和外观图的对象实例挖掘方法,可以显著提高训练后的模型判别能力。
(2)为了学习更精确的CNN分类器,提出了一种通过调整不同实例的损失函数权重来重新加权损失。
相关工作:
(1)OICR:容易陷入局部最优;
(2)PCL:部分区域的物体(part of the object)容易被忽略;
(3)C-WSL:需要额外人工标注成本。
二。方法
1. 总体架构
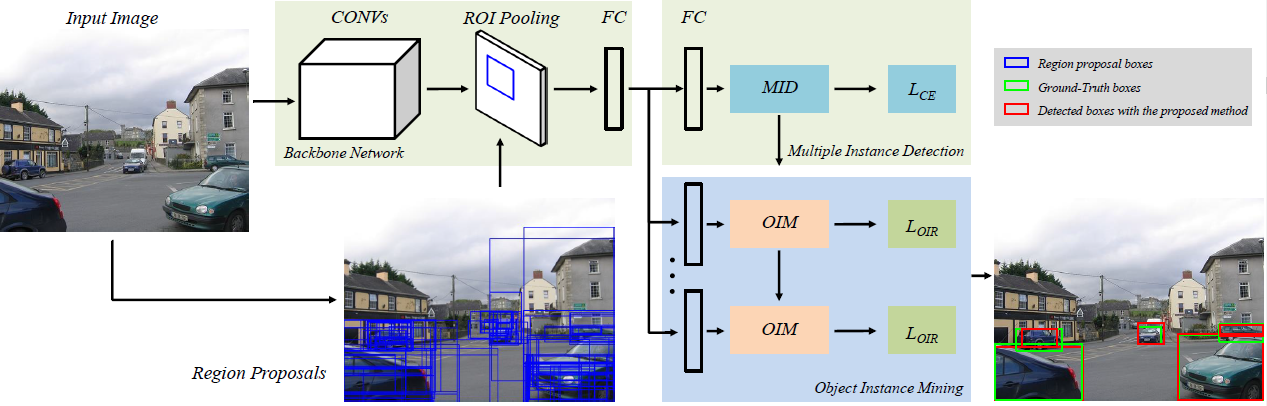
模型总体架构。$ L_{CE} $ 代表多类别交叉熵损失函数, $ L_{OIR} $ 代表实例重加权损失函数。
2. OIM
以往的方法中,通常选择得分最高的proposal及其周围重叠度高的proposals作为正样本,这会限制模型性能。因为很多情况下,一张图片中有多个对象属于同一类别。被忽略的对象实例可能会被认为是负样本,从而在训练中降低WSOD模型性能。所以本文建立OIM方法,通过建立空间和外观图在一张图片中搜索所有可能的对象实例,并将其投入训练过程。

1 | 在C类上遍历: |
OIM算法伪代码。$ p_{ic} $ 为核心proposal,$ x_{ic} $ 为最高置信度的proposal的分数。核心空间图可以用$ G_{ic}^{S} = ( V_{ic}^{S} , E_{ic}^{S} ) $ 表示。$V_{ic}^{S}$中的每一个节点表示被选择的proposal与核心实例的IoU(即空间相似度)大于阈值T。$E_{ic}^{S} $ 中的每一条边表示空间相似度。空间图$ G_{ic}^{S} $中的所有节点将被选择并标记为与$ p_{ic} $ 相同的类别。
我们将每个proposal的特征向量定义为$F$,外观图定义为:$ G^{a} = ( V^{a} , E^{a} ) $ ,$V^{a}$中的每个节点都是与核心实例具有高外观相似度的proposal,$E^{a}$中的每条边表示外观相似程度。这种相似性可以使用欧氏距离从核心实例的特征向量和其他proposal之一(例如$p_{j}$)中计算出来。
只有当proposal$p_{j}$满足条件:$D_{ic, j} < \alpha D_{avg}$ 并且$p_{j}$与其他之前选过的proposals无重叠时才会被加入$ G^{a} $ 中的节点。 $D_{avg}$ 表示$G_{ic}^{S}$的平均类内相似度,使用$G_{ic}^{S}$中所有节点的平均距离。可以进行如下定义:
其中$p_{k}$表示满足上述要求的节点,$M$表示$G_{ic}^{S}$中节点的数量。$\alpha$是由试验确定的超参数。
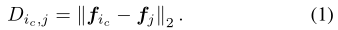
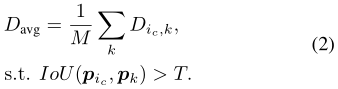
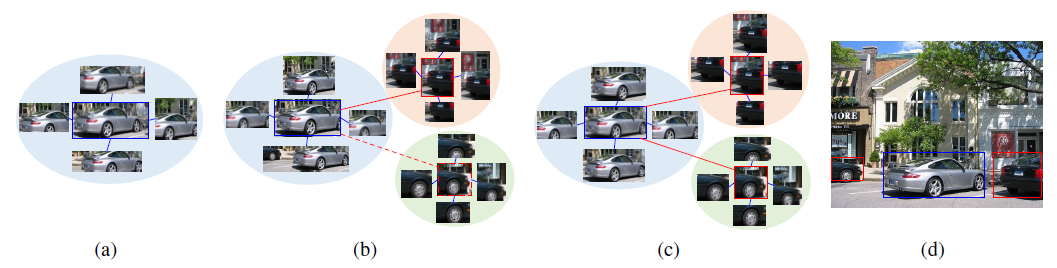
上图展示了使用空间图和外观图检测同一类中所有可能的对象实例的过程。 (a)是核心空间图,(b)-(c)描述了不同epoch的空间图和外观图,(d)展示了所有检测出的实例。可见,随着迭代次数的增加,可以使用OIM检测更多的实例。蓝色边界框表示检测到的具有最高置信度得分的核心实例。红色边界框表示与核心实例具有高度外观相似性的其他检测到的实例。蓝线和红线分别代表空间和外观图的边。(b)中的红色虚线表示外观相似性小于阈值,因此在此阶段不使用对象实例。
3. 实例重加权损失
本文建议为每个proposal分配不同的权重,以平衡得分最高的proposal和显著性较小的proposal的权重。因此,每个实例的较大部分都有可能被检测到。
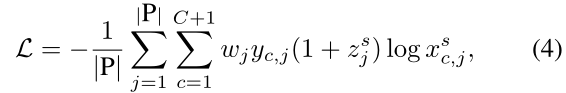
其中: