R-CNN、Fast R-CNN、Faster R-CNN学习笔记。
R-CNN
题目:Rich feature hierarchies for accurate object detection and semantic segmentation
Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik;2014
Fast R-CNN
摘要
Fast R-CNN 在 R-CNN 和 SPPnets 的基础上优化,比 R-CNN 和 SPPnets 更快更准。
介绍
R-CNN的缺点
- 训练是一个多阶段的过程:首先,使用log损失函数在对象建议框上迁移学习。其次,对卷积层的特征图使用SVM分类,SVM作为物体检测器,替代了softmax分类器。训练最后的阶段,学习bbox回归。
- 训练消耗时间和空间:对于SVM和包围盒回归器训练,从每个图像中的每个对象建议中提取特征并写入磁盘。对于非常深的网络,例如VGG16,这个过程需要2.5个GPU-days来处理VOC07训练集的5k张图像。这些功能需要数百GB的存储空间。
- 物体检测速度很慢:在测试时,从每个测试图像中的每个对象建议中提取特征。VGG16检测每张图片需要47s (在GPU上)。
R-CNN速度很慢是因为它的每一个建议区域都要分别执行卷积计算,没有共享计算。SPPnets被提出通过共享计算来加速R-CNN。
SPPnet方法计算整个输入图像的卷积特征图,然后使用从共享特征图中提取的特征向量对每个对象建议进行分类。通过最大池化将候选框内的特征图转化为固定大小的输出(例如6×6)来提取针对候选框的特征。多个输出大小被合并,然后像空间金字塔合并一样连接在一起。SPPnet在测试时间加速R-CNN 10到100倍。由于更快的建议特征提取,训练时间也减少了3倍。
SPP网络也有显著的缺点。像R-CNN一样,训练过程是一个多级pipeline,涉及提取特征、使用log损失对网络进行fine-tuning、训练SVM分类器以及最后拟合检测框回归。特征也要写入磁盘。但与R-CNN不同,在SPPnets文章中提出的fine-tuning算法不能更新在空间金字塔池之前的卷积层。不出所料,这种局限性(固定的卷积层)限制了深层网络的精度。
贡献
我们提出了一种新的训练算法,该算法在提高速度和精度的同时,弥补了R-CNN和SPPnet的不足。我们称这种方法为Fast R-CNN。Fast R-CNN有几个优点:
- 检测质量(mAP)高于R-CNN、SPPnet
- 训练是单阶段的,使用多任务损失
- 训练可以更新所有网络层
- 特征缓存不需要磁盘存储
Fast R-CNN is written in Python and C++ (Caffe[13]):https://github.com/rbgirshick/fast-rcnn.
Fast R-CNN的结构和训练
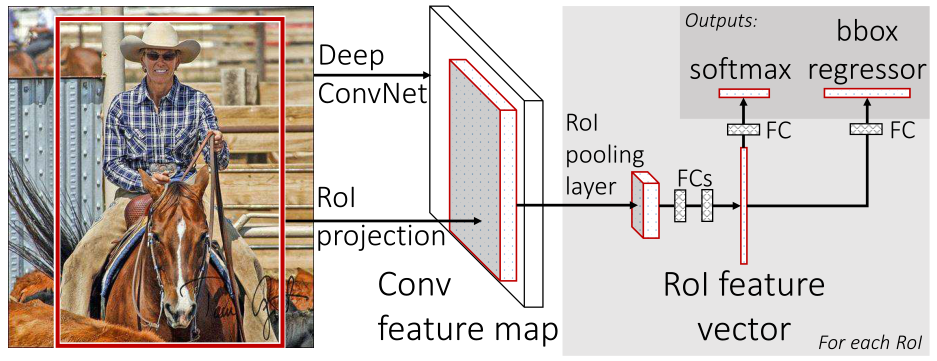
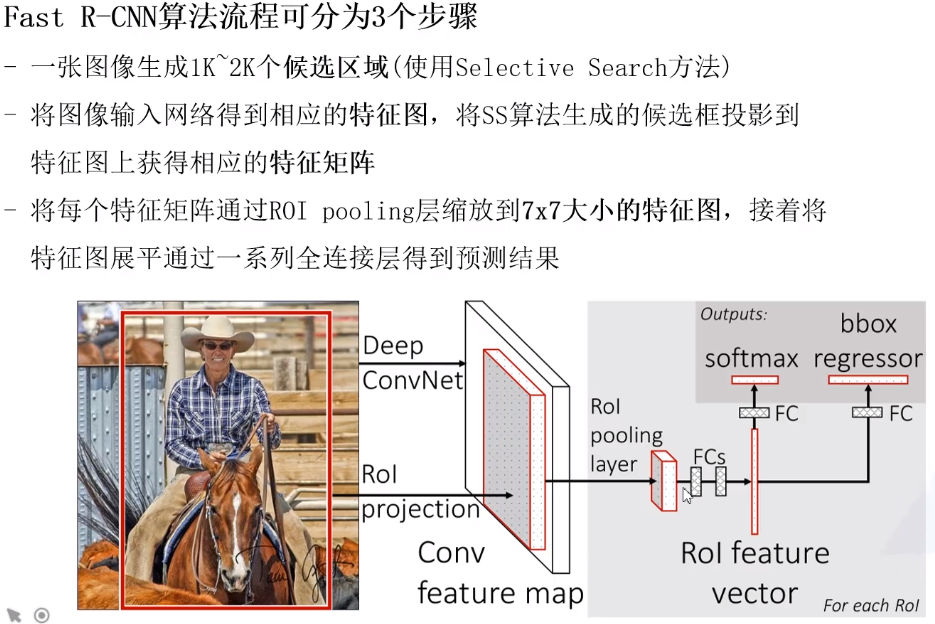
图1. Fast R-CNN架构。输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中。每个RoI被池化到固定大小的特征图中,然后通过全连接层(FC)映射到特征向量。网络对于每个RoI具有两个输出向量:Softmax概率和每类bounding-box回归偏移量。该架构是使用多任务损失进行端到端训练的。
Fast R-CNN网络将整个图像和一组候选框作为输入。网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :一个输出K个类别加上1个包含所有背景类别的Softmax概率估计,另一个层输出K个类别的每一个类别输出四个实数值。每组4个值表示K个类别中一个类别的修正后检测框位置。
RoI 池化层
RoI池化层使用最大池化将任何有效的RoI内的特征转换成具有H×W(例如,7×7)的固定空间范围的小特征图,其中H和W是层的超参数,独立于任何特定的RoI。在本文中,RoI是卷积特征图中的一个矩形窗口。每个RoI由指定其左上角(r,c)及其高度和宽度(h,w)的四元组(r,c,h,w)定义。
RoI最大池化通过将大小为h×w的RoI窗口分割成H×W个网格,子窗口大小约为h/H×w/W,然后对每个子窗口执行最大池化,并将输出合并到相应的输出网格单元中。同标准的最大池化一样,池化操作独立应用于每个特征图通道。RoI层只是SPPnets[11]中使用的空间金字塔池层的特例,其只有一个金字塔层。我们使用[11]中给出的池化子窗口计算方法。
初始化预训练网络
首先,最后的最大池化层由RoI池层代替,其将H和W设置为与网络的第一个全连接层兼容的配置(例如,对于VGG16,H=W=7)。
其次,网络的最后一个全连接层和Softmax(其被训练用于1000类ImageNet分类)被替换为前面描述的两个同级层(全连接层和K+1个类别的Softmax以及特定类别的bounding-box回归)。
最后,网络被修改为采用两个数据输入:图像的列表和这些图像中的RoI的列表。
Fine-tuning for Detection
Multi-task loss
Fast R-CNN有两个并行输出层。

$p$是分类器预测的softmax概率分布,$p = (p_0,…,p_K)$
$u$对应目标真实类别标签
$t^u$对应边界框回归器预测的对应类别u的回归参数$(t_{x}^k, t_{y}^k, t_{w}^k, t_{h}^k)$
$v$对应真实目标的边界框回归参数$(v_x, v_y, v_w, v_h)$
—— 分类损失函数:

$p_u$越大,$logp_u$越大,$-logp_u$越小,即损失越小($p_u$为预测为真实值的概率)
—— 边界框回归损失函数:

$\lambda$为平衡系数,用于平衡分类损失和边界框回归损失。
$[u\geq1]$为艾佛森括号,当$u\geq1$时,值为1,否则为0。意义:$u\geq1$时,代表候选区域标签为真实目标,才需要计算边界框回归损失,否则为分类失败,则不需要计算回归损失。
—— 总览:
Faster R-CNN
摘要
接近实时目标检测的网络。