Multiple Instance Detection Network with Online Instance Classifier Refinement
华中科大 2017
一。介绍
我们通过改进WSDDN提出了MIDN。
实际上,有两个重要问题。
如何初始化实例标签,因为没有实例级的监督。
如何高效地用实例分类器训练网络。分类器细化的一种自然方式是替代策略,即交替地重新标记实例和训练实例分类器,而这一过程非常耗时,特别是考虑到训练具有大量随机梯度下降(SGD)迭代的深层网络。为了克服这些困难,我们提出了一种新的在线实例分类器精化(OICR)算法来在线训练网络。
我们的主要贡献如下:
- 我们提出了一个弱监督学习框架,结合MIDN和多阶段实例分类器。只需监督前一阶段的输出,实例分类器的识别能力就可以迭代地得到增强。
- 我们进一步设计了一种新的OICR算法,该算法将基本检测网络和多级实例级分类器集成到单个网络中。提议的网络是端到端可训练的。与交替训练策略相比,该方法不仅能减少训练时间,而且能提高性能。
- 在PASCAL VOC 2007和2012基准上,我们的方法比以前弱监督目标检测的最先进的方法获得了显著更好的结果。
二。相关工作
MIL:
如果一个包是正的,那么包中至少有一个实例是正的;
如果一个包是负的,那么包中的所有实例都是负的。
所以将WSOD视为MIL问题是很自然的。问题就变成了在只给定包标签(bag labels)的情况下去寻找一个实例(instances)分类器。
三。方法
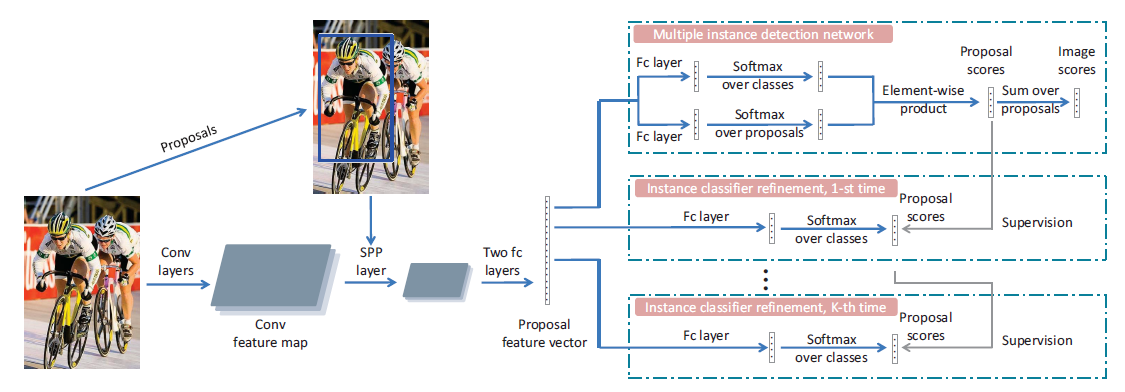
proposal feature vectors(建议区域特征向量) are branched into many streams for different
stages. All these stages share the same proposal representations.
我们的方法的整体架构如上图所示。给定一个图像,我们首先通过选择性搜索生成大约2000个对象建议。图像和这些提议被馈送到具有空间金字塔池化(SPP)层的一些卷积(conv)层,以产生每个提议的固定大小的conv特征图,然后它们被馈送到两个全连接(fc)层,以产生提议特征向量的集合。这些特征被分支成不同的流,即不同的阶段:第一个是MIDN,训练一个基本的实例分类器,其他的给精炼分类器。
MIDN(Multiple instance detection network)
训练精炼分类器需要实例(对象)级的监督,但这种监督是没有的。而实例分类器的最高分建议区域和它的相邻建议区域可以被标记到它的图像标签上作为监督。所以我们首先引入我们的MIDN来生成基础实例分类器。实现这个有很多可能的选择,在这里,我们选择了WSDDN的方法,因为这种方法的有效性并且便于实现,该方法提出了一种加权池化策略来获得实例分类器。
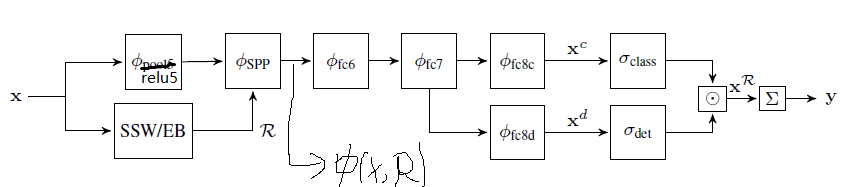
$$
\phi(X; R)=\phi_{SPP}(·;R)\circ\phi_{relu5}(X)
$$
X为输入的图片,R为候选区域。接下来,区域级别的特征进一步被fc6和fc7处理,然后输出两个流,分别被fc8c和fc8d处理。
分类数据流:
通过fc8c后得到$X^c$,然后通过softmax得到$\sigma_{class}$。
检测数据流
通过fc8d后得到$X^d$,然后通过softmax得到$\sigma_{det}$。
结合区域和检测分数(元素点乘)
图像级分类分数
如框架图中的MIDN block所示,建议区域特征被分为两个流,产生了两个矩阵:$ X^c,X^d \in \mathbb{R}^{C\times|R|}$,其中$C$表示图片的类的个数,$|R|$表示候选区域的个数。
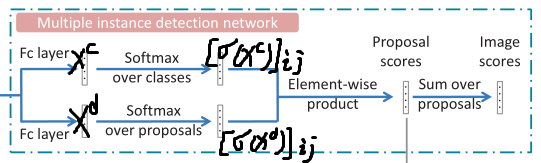
对于两个流的解释:$ [\sigma(X^c)]_{ij} $指建议区域j属于类别i的概率。
$ [\sigma(X^d)]_{ij} $指normalized weight,指图片被分类为i类时建议区域j作的贡献。
$ y_c = 1$代表图片中有c类,$y_c=0$代表图片中无c类
我们通过多类交叉熵损失函数训练基本实例分类器,公式如下:
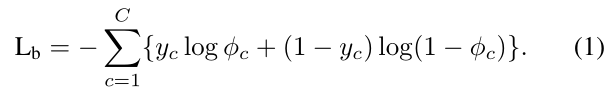
OICR(Online instance classifier refinement)
上面的部分,我们得到了基本实例分类器。
困难在于,如何在无带标签实例的情况下获取实例标签以进行精炼 ——> 提出在线标注和精炼方法。
与基础实例分类器不同,OICR中建议区域j的输出得分向量$ X_{j}^{Rk} $是C+1维向量,其中k代表精炼了第k轮,基础实例分类器输出的建议区域分数为$ X_{j}^{R0} $。
通过将建议区域的特征向量输入到单个fc层和“softmax over classes”层,获得$X_{j}^{Rk}$,k>0(见下面结构图)


输入:图片和建议区域;图片标签向量Y;精炼次数K
输出:损失权重;建议区域标签向量,其中r是建议区域的个数,k是精炼次数
基本实例分类器损失:
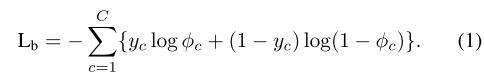
各轮refinement的Loss和,第k轮的refinement的Loss形式如下:
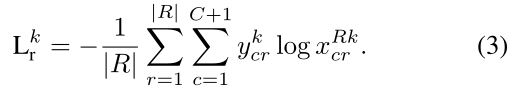
实际上,训练刚开始时结果很不可靠,所以我们将损失函数(3)变为下面的加权损失函数(4):
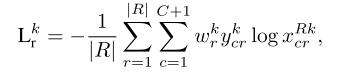
$w_{r}^k$可以从OICR伪代码的第十一行获得。刚开始时,$w_{r}^k$较小,所以损失函数(4)也较小,所以网络的性能不会下降很多,好的正实例不会被发现。随着训练的进行,网络可获得高的分数,在简单图像的正实例上,即$w_{r}^k$会变大。另一方面,很难在困难图像上获得负实例,这会导致这些正实例经常很noisy。
然而,精炼后的分类器不会偏离正确的解决方案太远,因为这些noisy的正实例的分数相对较低,即:$w_{r}^k$很小。
在OICR伪代码中,$I_r$代表proposal r与最高的proposal的IoU。一系列操作后,我们可通过结合公式(1)、(4)得到公式(5)。得到总体损失:
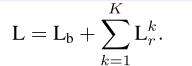
通过优化此损失函数,我们可以将MIDN与OICR集成到单个网络中,并在不同阶段共享表示(representations)。
四。实验
数据集和评估方法
数据集:PASCAL VOC 07 (9,962 IMAGES) & PASCAL VOC 12 (22,531 IMAGES) 各自拥有20类。这两个数据集分为训练集、val集和测试集。
本文选择trainval 集(VOC 07选择5011张图片、VOC 12选择11540张图片)去训练我们的网络。因为我们关注弱监督检测时,在训练期间仅使用图像级标签。
评估方法:对于测试,AP、mAP是在测试集上测试我们模型的评估准则。CorLoc在训练集上测试我们的模型以衡量定位精度。两种准则都符合Pascal VOC 准则。即:GT box 和 预测box间的IoU > 0.5
实现细节
我们的方法基于两个预训练模型:VGG_M和VGG16,它们都有一些卷积层和最大池化层以及三个fc层。我们将两个模型的最大池化层换成SPP层。最后一个fc层和最大softmax层,由第3节中描述的层构成。
为了从最后一个卷积层增加特征图的大小,我们用扩大的卷积层替换倒数第二个最大池化层及其后续的卷积层,新添加的层使用均值为0,方差为0.01的高斯分布初始化,偏置初始化为0。
在训练过程中,SGD的mini-batch设置为2,在最初的40K轮迭代( iterations )中,学习率设置为0.001,接着在接下来的30K轮迭代中下降到0.0001。momentum和weight decay分别设置为0.9和0.0005。
Selective Search被用于给每张图片生成约2000个proposals。为了数据增强,我们使用5种图片尺度:{480,576,688,864,1200}(调整最短的边),在训练和测试中,用水平翻转将最长图像侧的长度限制在2000以内。
我们精炼模型3次,即K=3。所以一共有4个阶段。伪代码第12行中的$I_t$设置为0.5。
在测试期间,选择这三个细化分类器的平均输出。我们通过选择由我们的方法给出的最高分建议作为伪gt来进一步改进我们的结果。
消融实验
instance classifier refinement的影响
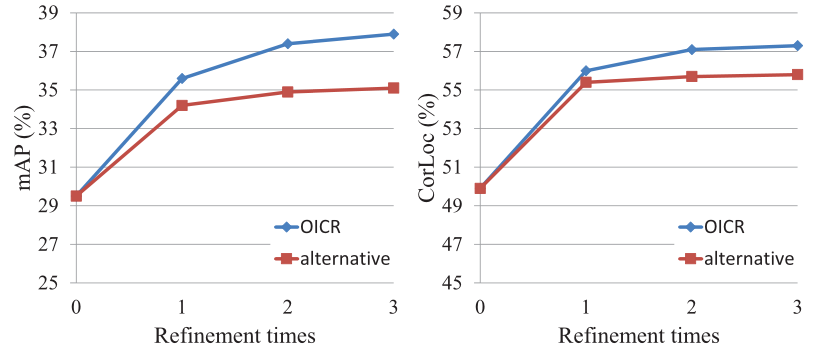
但随着精炼次数增加,网络趋向于收敛。
OICR的影响
通过上图能发现,随着精炼次数的增加,alternative 策略和OICR策略都能提高效果,但是OICR提升的效果更显著,这也确定了共享表示的重要性。与此同时,OICR能减少大量的时间,因为它只需要训练一次模型,而不像alternative策略中第k次精炼需要训练k+1次模型。
权重损失的影响
无权重损失($ w_{r}^{k} $)时,OICR的效果比alternative策略更差。
IoU阈值的影响
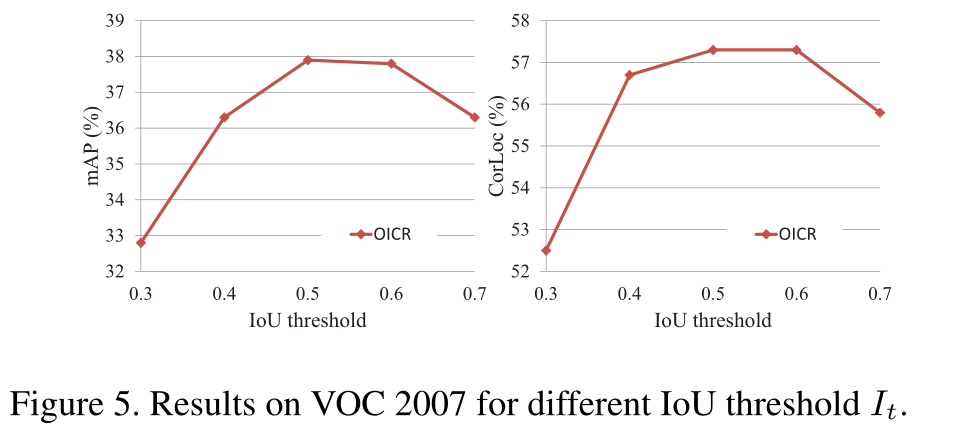
由图,故设置为0.5。
